Dependency Injection for Modern Swift Applications Part I
Managing Dependencies in the Age of SwiftUI
Author: Lucas van Dongen
Introduction
Welcome to Part I of my series about Dependency Injection for Modern Swift Applications. The other parts already published are:
Dependency Injection (or in short: DI) is one of the most fundamental parts of structuring any kind of software application. If you do DI right, it gets a lot easier to change and extend your application in a safe manner. But if you get it wrong, it can become increasingly more difficult to ship your features in a timely, correct and safe way.
Apple notoriously has been quite unopinionated about Dependency Injection in its development frameworks until recently, when it introduced EnvironmentObject for SwiftUI.
But does having an Apple-standard way of doing DI settle the discussion once and for all?
In this blog post I will talk you through:
- The two fundamental approaches to consuming dependencies
- The two ways dependencies are distributed
- The five most important issues to consider before selecting a DI solution
This blog post is aimed at people with intermediate to advanced skills in Swift and SwiftUI.
The Example Diagrams
Throughout the article I will illustrate the workings and challenges for each approach using diagrams. It represents a dependency hierarchy of a Root node connecting to child nodes two layers deep. This could equally be the @main App, the UIApplicationDelegate or any other entry point you can imagine in an app.
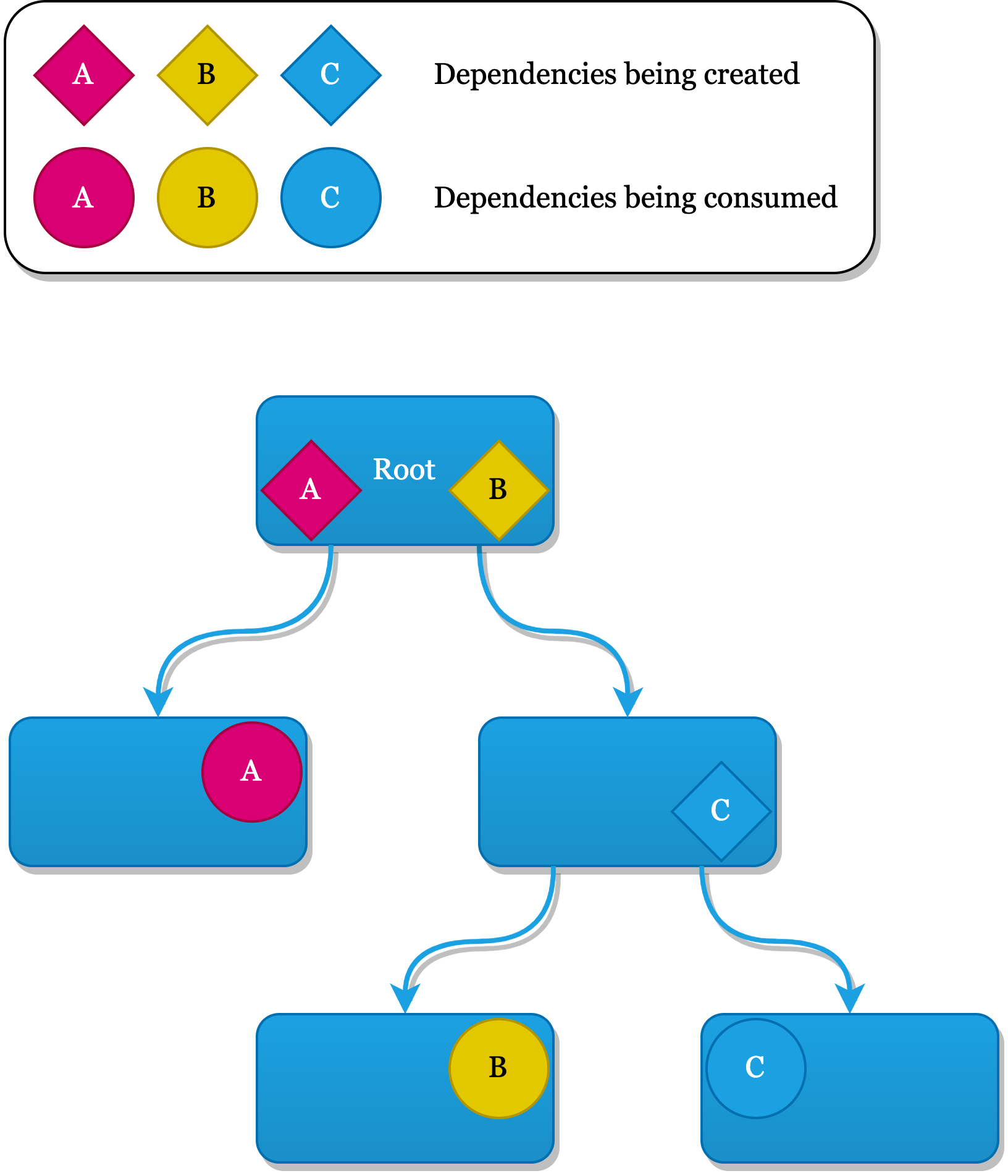
- The hierarchy mimics a View and navigation hierarchy
- A diamond shape indicates where various dependencies (A, B and C) are being created in our hierarchy
- The point where are consumed in a child or grandchild node is indicated by a circle shape
- Pay special attention to dependency C: it can not be created right away, but only at a later point in this app's lifecycle!
We could also have a more service-oriented application where dependencies and their lifecycles are more decoupled from the UI. In that case the diagram would look more like a network.
But, assuming that most of you work on UI driven iOS applications, the tree is the most common structure.
How are Dependencies Consumed?
Using the Initializer, Pushing Dependencies
When you pass all of the dependencies for a given instance through the initializer there is no ambiguity if a given dependency will be there when it's needed. In the PassedDependencies example, the LogInView needs an Authentication component to log in the user, followed by the LogInSwitcher that can switch the application back and forth between authenticated and logging in state:
struct LogInView: View {
let authentication: Authenticating
let logInSwitcher: LogInSwitching
var body: some View {
Button {
authenticate()
} label: {
Text("Log In")
}
}
private func authenticate() {
Task {
do {
let token = try await authentication.authenticate()
logInSwitcher.tokenPublisher.send(token)
} catch let error {
}
}
}
}It takes all ambiguity out of the system, but passing forward dependencies can become a real chore when an application grows. Good luck if you need a component that was created in a deep branch all the way deep into another branch from the root: you will have to refactor dozens of files just to make sure all of the intermediate files pass it forward.
Also, the intermediate nodes will now know about a dependency that is not directly used by them. This violates the Single Responsibility principle, adding the responsibility of passing through dependencies to every node in between.
Many teams try to solve this by using Builder or Factory patterns (not to be confused with Factory, the DI framework, which we'll review later). But they alleviate complexity in one side while making other things more complex, because it works better in a more flattened hierarchy. In that way you can just use a few nested factories that unlock various stages of dependencies (for example, after authenticating and obtaining a network token).
Using a Service Locator, Requesting Dependencies
The alternative to pushing dependencies through the initializer is a form of the Service Locator Pattern. This way, the instance will not have it's dependencies passed implicitly through the initializer, but it will request them from the system.
It is very good for decoupling components, taking the burden of understanding what a child component needs in terms of dependencies away from the parent node that creates it. Apple's own EnvironmentObject works this way:
struct LogInView: View {
@Environment(\.authentication) var authentication: Authentication
@EnvironmentObject var logInSwitcher: LogInSwitcher
…
}It will ask at run-time the value for the given dependency in the registry used for Environment.
There are some steep downsides to this. In the example of EnvironmentObject the application crashes if it hasn't been set somehwere up the tree. Other Service Locator derived solutions like Factory force you to either set the dependency right when the app start, or start out with a dummy or nil value to replace it later.
An example using the Factory library to illustrate the latter problem:
class AppViewModel: ObservableObject {
@Published private(set) var state: AppState = .loggedOut
private var cancelBag = Set<AnyCancellable>()
init() {
observeState()
}
// …
func observeState() {
$state.map { state in
switch state {
case let .authenticated(token):
UserManager(token: token)
case .loggedOut:
PlaceholderUserManager()
}
}.sink { userManager in
Container.shared.userManager.register { userManager }
}.store(in: &cancelBag)
}
}We need to be careful to register the actual UserManager implementation we want for the .authenticated node of the application, but also to remove it again when we log out again because it contains sensitive user information, like in this example the token.
Another variant on this is setting and resetting the token on UserManager, making it throw an Error if the token is not set.
In both cases the solution has one and the same problem: globally mutable state.
What Approaches to Distributing Dependencies Exist?
Tree-Based Approach
The tree-based approach is very simple and it is the only other alternative to statically declared dependencies when we are not using some kind of framework for DI. It simply means that all required dependencies are passed forward, bucket-brigade style, through the lifecycle and View hierarchy of your application:
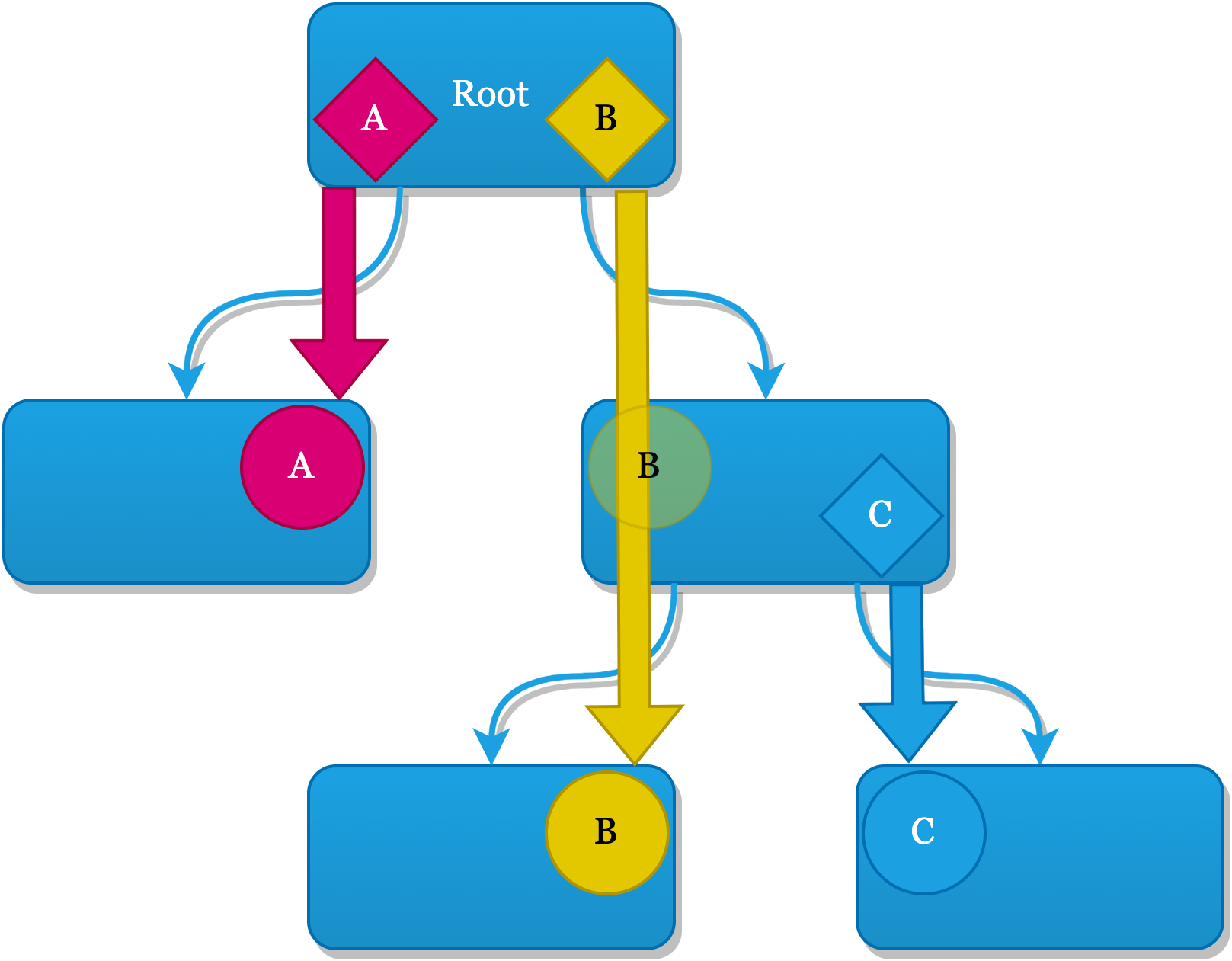
In this diagram you see that all dependencies are explicitly passed down the tree until they reach the node that needs it. This works great as it has the following advantages:
- If the application builds, you know dependencies are passed correctly
- When you use protocols for the dependencies, it's easy to mock them
- Dependencies are only created when they are needed and when all sub-dependencies are in place, for example:
- We received a valid authentication
tokenand now have all of the dependencies to for ourUserManager - We received a valid quote from the back-end that we need to be able to finish our purchase by sending a confirmation request
- We received a valid authentication
This last advantage is perfectly explained by Sundell in his "Locks and Keys" section in one of his talks, that had a profound impact on the way I was thinking about dependencies.
You will never see non-optional optionals or crashes through trying to force a dependency reference that is not there yet.
Often there are just a few moments that you "unlock" new dependencies and it's easy to bundle all of those dependencies into a classes or structs that can be passed forward more easily than individual dependencies.
But it does often mean that classes closer to the root have to deal with dependencies that are only relevant to sometimes remote branches, as you see in the diagram: the middle node now needs to pass forward dependency B while it has no use for it.
Most trees in applications are much larger than this, and passing forward all of the dependencies can become a chore. But worse, the nodes become tightly coupled. This will make it harder and harder to refactor and reuse components.
Statically Declared Approach: Singletons on Steroids
The statically declared approach is a remote cousin of the Singleton, where all dependencies are in some kind of way statically defined and accessed. It does not mean they are all created immediately, usually they are lazily initialized when accessed for the very first time and often there are optional rules for defining their lifecycles.
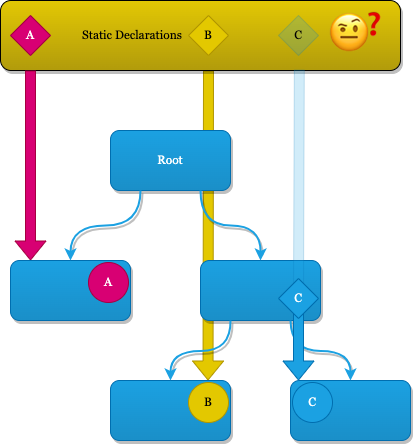
When working with statically declared dependencies, as shown in the diagram, we distribute dependencies completely outside of the tree of nodes, which removes the responsibility of creating and passing dependencies completely.
This removes the tight coupling of components and makes it much easier to introduce and change dependencies and refactor your code. Last but not least, dependency structures that are not tree-shaped are much easier to realize.
However it introduces the same problem as the Service Locator approach has: when a dependency (like dependency C in this example) cannot be constructed right when the app starts, we have a problem that is not easy to solve. How does the node that consumes dependency C have the guarantee that it has been created? And how does it handle the edge cases where this didn't happen yet?
Common Anti-Patterns for Static Dependencies
You might have an issue with a static dependency solution if you see any of the following code smells:
- A dependency is set to
nilor a placeholder value until the moment it can actually be created - You're manually shuffling back and forth between real and placeholder value depending on the state of your app
There is no truly satisfactory solution for unlocking a dependency at exactly the right moment using statically declared dependencies.
What Kind of Challenges Does a DI Solution Face?
The strategy of distributing your dependencies is always a game of trade-offs. The only thing that I can do is help you better understand the different trade-offs that exist and then evaluate these trade-offs when I will review some well-known solutions further on.
Usability
If you would drop a new developer into your codebase today, how long would it take them to grok your dependency structure and use your DI method in the correct way? But also: how hard is it to add or edit features.
I've been in situations where the DI framework of choice required quite a bit of study. Other DI solutions were simply cumbersome and required extensive changes across numerous files to position a single dependency correctly.
The harder it gets to do the right thing, the more tempting becomes doing the wrong thing.
Testability and Previews
When we are writing tests or want to generate Previews we don't want to deal with the whole tree of dependencies just to test one subsystem or to generate one small View for Previewing or snapshotting.
Instead we want to use mocks, spies and stubs to ensure the system under test always generates the same output for the same input and we're not dealing with the complexities of the dependencies we don't care about in that context.
So it should be possible and ideally also easy to swap out your real dependencies with mocked versions when running your tests and previews.
Scaling
A scaling issue means that you increase a certain number until your current approach stops being a valid approach and you need to search for an alternative.
Some of the metrics that are related to scaling:
- The amount of dependencies or modules we need to manage
- The amount of developers working on the project
- The time it takes to execute a full suite of tests
- The build time of our application
- The app's overall performance
App launch time is a very important metric once the amount of dependencies and the general complexity of your app increases over time. Creating all dependencies immediately when the app is launching will increase that metric.
A well scaling solution means it's either working well for all scales, or it becomes a feasible solution once a certain scale is reached because its drawbacks no longer outweigh its advantages.
Compile-Time Safety
The compiler is a great tool to validate the correctness of your program. In fact, the number one feature that makes Swift developers wish they could use their language everywhere is the compile safety guarantees that the language gives. When you use the language idiomatically you will not see any nil pointer or type related crashes at run-time. Game changer!
It's natural that Swift developers want to extend that compile-time security to every area, including Dependency Injection. A compile-safe DI solution ensures that if the application compiles, all DI requirements will be guaranteed to be set when the applications runs.
A DI solution should never be the cause a crash or unexpected behavior during run-time - not even in edge cases.
Generational Safety
Generational (or Timeline) Safety is often overlooked when discussing DI solutions because it's a more rare and harder to understand concept. In fact I had a hard time coming up with the right term for it as I could not find good web sources explaining the problem or defining a name for it. However for me this is a vital concern, as we don't always have every Dependency available when the Application starts.
If you do know a better term or have a good source that explains this problem, please share!
Some dependencies only get unlocked because either the Application or the User unlocks a certain functionality. For example, the user unlocks a session after authentication successfully, which in turn can be used to access a secure endpoint. You cannot create any type of depenency that relies on data in your Keychain until it becomes available.
Even the most simple applications usually have one or two of these changes later on their lifecycles that unlock one or more required dependencies.
True Generational Safety ensures that whenever a given dependency is requested it exists, even when the given dependency can only be constructed later on in an Appliction's life-cycle. An example of this in our diagrams is dependency C.
Conclusion of Part I
We now wrapped up the more theoretical part of Dependency Injection in Swift and especially SwiftUI, highlighting some of possibilities and problems all differerent approaches can have.
It already became clear that it's hard to have an easy-to-use, flexible and well-isolated approach to DI while at the same time retain run-time and compile-time safety.
Dependencies that are consumed by some form of Service Locator have issues with either stability or correctness. You lose the "if it compiles, it works" guarantee we grew to love for many concepts in Swift. But direct injection of dependencies through the initializer is laborious and needs further layers of abstraction like Factories to remove the burden of dependency propagation from intermediate nodes.
Part II: Four Approaches Compared
After seeing what are the parameters are necessary to judge a good DI solution, it's time to get hands on and build a small (but just complex enough) application with all of these approaches. We can then directly compare how the behave differently and compare their pros and cons by analyzing the code for each of them.
Part II of Dependency Injection for Modern Swift Applications will to apply all of these concepts in real life scenarios using various different approaches or frameworks:
Updated on the 2nd of March 2024, revising some terminology used and the way swift-dependencies (TCA) was evaluated
Updated again on March the 22nd 2024, moving the comparisons of the individual frameworks towards a new article and (hopefully temporarily) removing TCA from the comparison
